Additions to the Myanmar Script in Unicode
 I was surfing the internet looking for more on the diæresis (note that I have used the more correct U+00E6 today) when I received notification of a proposal that included this dear little thing. Not a diæresis after all, it is the proposed character MYANMAR VOWEL SIGN GEBA KAREN I U+1097.
I was surfing the internet looking for more on the diæresis (note that I have used the more correct U+00E6 today) when I received notification of a proposal that included this dear little thing. Not a diæresis after all, it is the proposed character MYANMAR VOWEL SIGN GEBA KAREN I U+1097. The usual MYANMAR VOWEL SIGN I is U+102D. (I have just used Babelmap to confirm that I am reading this correctly.)
The usual MYANMAR VOWEL SIGN I is U+102D. (I have just used Babelmap to confirm that I am reading this correctly.)
The argument reads that since both vowel signs can appear together in text, albeit a grammar text, they need to be represented by different codepoints, so the different glyph (shape) can be represented in plain text, and not just by a different font.
The entire document was recently released here. Preliminary proposal for encoding Karen, Shan, and Kayah characters in the UCS.
Here is a text from this document showing the Karen vowel sign I and the Myanmar vowel sign I. I recommend the entire document. Many new characters are proposed.
Update: The previous title 'Myanmar Block Unicode Proposal' was truly terrible. I was thinking that it was the Mayanmar 'block' in Unicode, not necessarily only Myanmar 'users' of the script. Then I went back to change the title and my wonderful spam blocker shut me out of blogger for a while. Thanks Paul for mentioning this.
posted by Suzanne McCarthy at 7:26 PM
9 comments
![]()
![]()


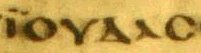



{kind=link}