சிற்றில் நற்றூண் பற்றி நின் மகன்
யாணடூளனோ ஏன வினவுதி ஏன் மகன்
யாண்டு உளன் ஆயினும் ஆறியேன் ஒரும்
புஸி சேரநது பொகிய கல் ஆலை போல
இன்ற வயிறோ இதுவே
தோன்றுவன் மாதோ போர்கள்ளத் தானே
'You stand against the pillar
of my hut and ask:
Where is your son?
I don't really know.
My womb was once
a lair
for that tiger
You can see him now
only in battlefields.'
Kavarpentu puranamuru 86 (transl A.K.Ramanujan 1985:184)
This is a poem cited by Sanford Steever in his article on Tamil in
World's Writing Systems edited by Peter T. Daniels and William Bright. This book has articles on 80 writing systems. My favourite characteristic of this book is the short selection provided in each writing system with a transliteration, transcription and translation.
(See the full version at the bottom of the page. I have omitted the transcription and left the transliteration unmarked by accents. I haven't learned to keyboard underdots and macrons yet. Sorry.)
I always find these selections reveal something about culture, human nature or both. I chose this poem to keyboard since I was in the mood to type a little Tamil.
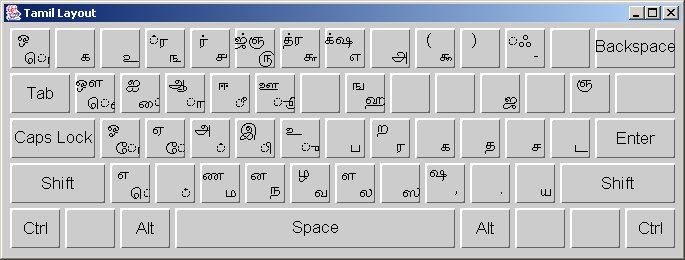
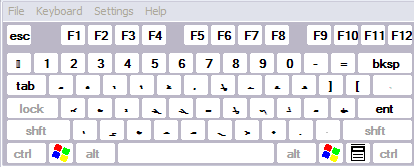
I started with the Inscript keyboard and soon found that I needed to use the shift key for every second letter. I had the on-screen keyboard from Start> Programs> Accessories> Accessibility> On-screen keyboard open. However, it only displays either the base state *or* the shift state not both at once. So hunt and peck didn't work. I then found that there were syllables in the text that I could not readily identify. This is not suprising given that World's Writing Systems uses a variant form of Tamil font.
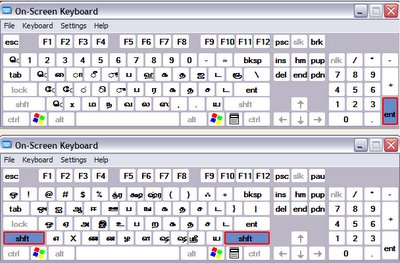 This is the Tamil keyboard in Windows. I have put the two together myself just to have a way to view them both at once.
This is the Tamil keyboard in Windows. I have put the two together myself just to have a way to view them both at once.
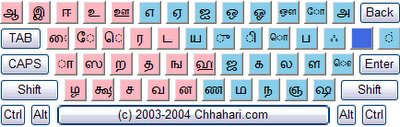
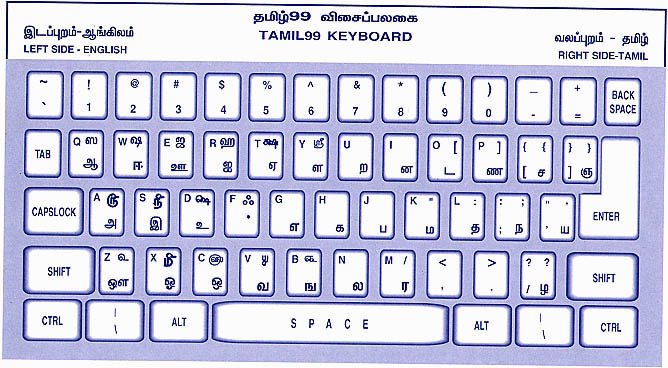
I finally ended up using the
Tamil phonetic (romanized) keyboard here with syllable display and that went well. Pretty easy once you get used to it. Actually there are two vowels where the shift key is needed. I had forgotten that.
Tamil is where it all began for me. I was working on a multilingual computing project a couple of years ago when I tried getting young people, who were somewhat familiar with typing Tamil in a previous encoding, to use the Inscript keyboard for Unicode Tamil. No way.
It took me over a year to get things sorted out for Tamil - I dropped the project and the rest is history. But if it weren't for this keyboard I would not have felt the need to connect with others and find out more about Unicode and related issues. Most other languages that we needed i.e. Chinese, Russian, Greek, Hebrew, Japanese, Korean and other Latin keyboards were no problem. Vietnamese ... well yes and no. Other languages just didn't seem available at the time.
Text of poem with transliteration and literal translation.
சிற்றில் நற்றூண் பற்றி நின் மகன்
cirril narrun parri nin makan
small house pillar leaning your son
யாணடூளனோ ஏன வினவுதி ஏன் மகன்
yantulano ena vinavuti en makan
where.is.he that you.ask my son
யாண்டு உளன் ஆயினும் ஆறியேன் ஒரும்
yantu ulan ayinum ariyen orum
where he.is that I.don't. know once
புஸி சேரநது பொகிய கல் ஆலை போல
puli cerntu pokiya kal alai pola
tiger joining going stone lair like
இன்ற வயிறோ இதுவே
inra vayiro ituve
begot womb this
தோன்றுவன் மாதோ போர்கள்ளத் தானே
tonruvan mato porkallat tane
appear indeed battlefield only
You stand against the pillar
of my hut and ask:
Where is your son?
I don't really know.
My womb was once
a lair
for that tiger
You can see him now
only in battlefields.
Kavarpentu puranamuru 86 (transl AKRamanujan 1985:184)
From Poems of Love and War, selected and translated by A.K. Ramanujan, 1985. Columbia University Press.
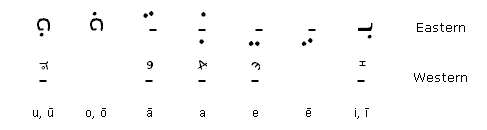 Last time I posted on Syriac I was asking myself about Syriac vowels. The vowels in the Eastern and Western versions of Syriac are quite different. I had actually assumed that they would be reflected in different fonts. I was surprised when I found out they they are encoded separately. I have no idea if this is a good thing or a bad thing.
Last time I posted on Syriac I was asking myself about Syriac vowels. The vowels in the Eastern and Western versions of Syriac are quite different. I had actually assumed that they would be reflected in different fonts. I was surprised when I found out they they are encoded separately. I have no idea if this is a good thing or a bad thing.

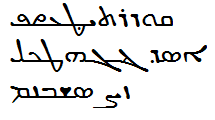
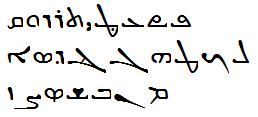

























{kind=link}
{kind=link}